深色模式
Kotlin 集合之 序列 Sequence
序列和迭代器的差别
对Iterable遍历执行多步操作时,会先对所有元素执行一个步骤,将结果保存到中间集合中,然后再对中间集合中所有元素执行下一个步骤,以此类推。相当于,所有元素被并行处理。
对Sequence遍历执行多步操作时,会对一个元素执行所有步骤,然后再对下一个元素执行所有步骤,以此类推。相当于,所有元素被串行处理。
序列的创建方式
通过元素创建
kotlin
val s1 = sequenceOf(1, 2, 3)通过Iterable创建
kotlin
val list = listOf(1,2,3)
val s2 = list.asSequence()通过generateSequence()函数创建
该函数有3种重载,都是用来定义如果生成第1个元素和下一个元素。当序列元素的计算函数返回null时,序列的生成过程会停止。
generateSequence(nextFunction: () -> T?): Sequence<T>generateSequence(seed: T?, nextFunction: (T) -> T?): Sequence<T>generateSequence(seedFunction: () -> T?, nextFunction: (T) -> T?): Sequence<T>
通过sequence()创建
sequence()函数可以逐个生成序列元素,这个函数的参数是一个lambda表达式,其中包括对yield()函数和yieldAll()函数的调用。这些函数会将元素返回给序列的使用者,然后暂停 sequence() 函数的执行,直到序列使用者请求下一个元素。
yield()的参数是单个元素。yieldAll()的参数可以是一个Iterable对象,或一个Iterator,或另一个Sequence。yieldAll()函数的Sequence参数可以是无限的。如果Sequence参数是无限的,yieldAll()必须出现在lambda的最末尾,否则,后面的代码将没有机会执行。
有些语言,把这个叫生成器,比如 Python。
序列的操作
举个栗子🌰
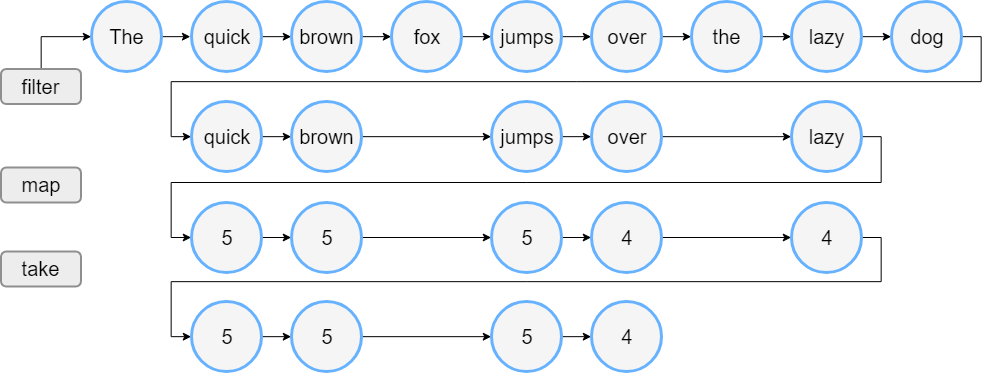
假设有很多单词,我们要过滤长度超过3个字母的单词,然后打印前4个这种单词的长度。
使用Iterable
代码:
kotlin
val words = "The quick brown fox jumps over the lazy dog".split(" ")
val lengthsList = words.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars:")
println(lengthsList)执行结果:
filter: The
filter: quick
filter: brown
filter: fox
filter: jumps
filter: over
filter: the
filter: lazy
filter: dog
length: 5
length: 5
length: 5
length: 4
length: 4
Lengths of first 4 words longer than 3 chars:
[5, 5, 5, 4]执行步骤图解:
使用Sequence
代码:
kotlin
val words = "The quick brown fox jumps over the lazy dog".split(" ")
// 将 List 转换为序列
val wordsSequence = words.asSequence()
val lengthsSequence = wordsSequence.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars")
// 终止操作: 以 List 形式获取结果
println(lengthsSequence.toList())执行结果:
Lengths of first 4 words longer than 3 chars
filter: The
filter: quick
length: 5
filter: brown
length: 5
filter: fox
filter: jumps
length: 5
filter: over
length: 4
[5, 5, 5, 4]代码执行图解:
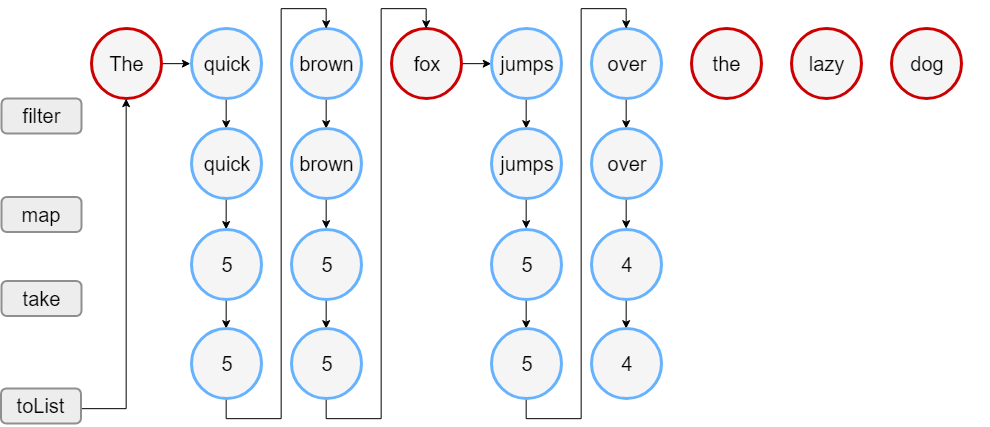
使用Sequence时的差异
filter()、map()和take()这些操作,在调用toList()后才开始执行。与上面Iterable的🌰相比,是”lazy“的。- 当结果元素数量到达4个时,会停止处理,因为
take(4)指定了最大元素数量。与上面Iterable的🌰相比,节省了操作步骤。 - Sequence处理执行了 18 步,而使用Iterable时则需要 23 步。